1.下載檔案
https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
2.上傳至ubuntu的/usr/local/路徑下
3.解壓縮
tar xvf spark-3.1.2-bin-hadoop3.2.tgz
mv spark-3.1.2-bin-hadoop3.2 spark
4.新增檔案/usr/local/spark/djt.log
hadoop hadoop hadoop spark spark spark
5.執行spark並進行字頻統計
/usr/local/spark/bin/spark-shell
val line = sc.textFile("/usr/local/spark/djt.log")
line.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)


6.standalone安裝
1) spark-env.sh
cd /usr/local/spark/conf cp spark-env.sh.template spark-env.sh mkdir /usr/local/spark/my-data
vi spark-env.sh
export JAVA_HOME=/usr/local/jdk export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export HADOOP_HOME=/usr/local/hadoop SPARK_Master_WEBUI_PORT=8888 SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=ubuntu-VirtualBox:2181 -Dspark.deploy.zookeeper.dir=/usr/local/spark/my-data"
2) slaves
cd /usr/local/spark/conf
vi slaves
ubuntu-VirtualBox
3) 啟動spark
因spark cluster需依賴zookeeper cluster,請先啟動zookeeper
/usr/local/zookeeper/bin/zkServer.sh start (需先啟動zookeeper)
/usr/local/spark/sbin/start-all.sh
jps
有以下process
Worker Jps QuorumPeerMain Master
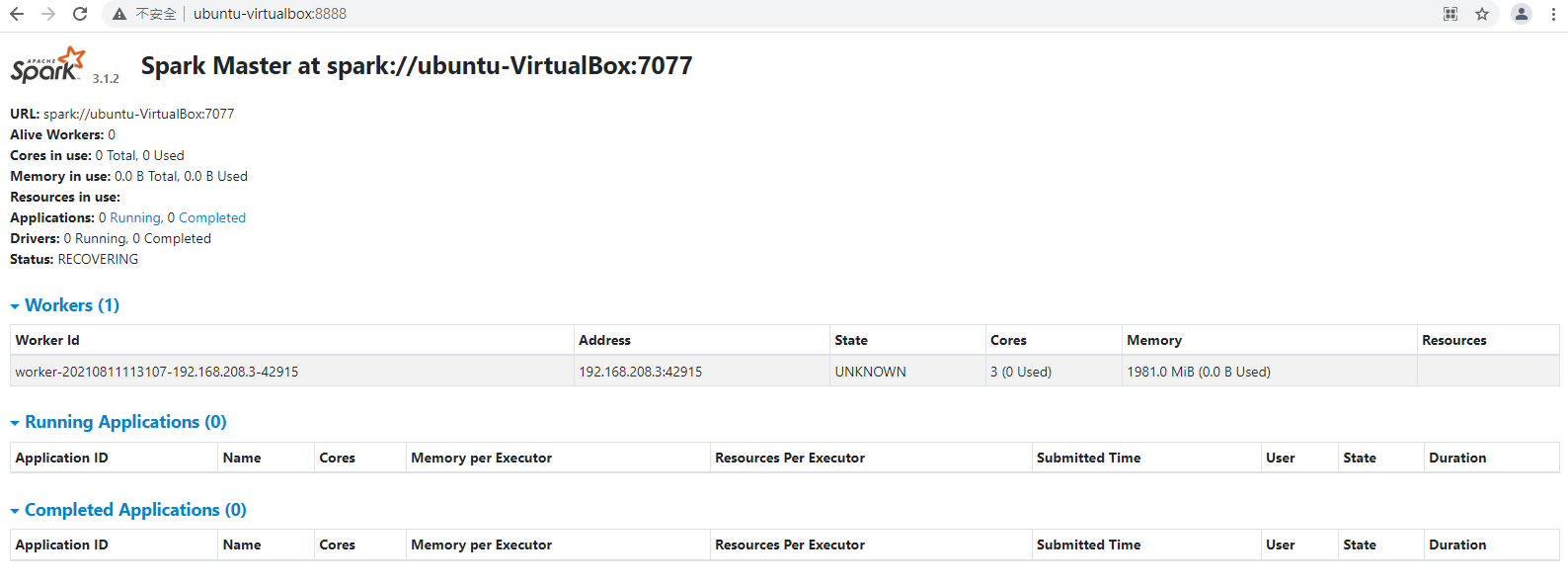
4) 查看瀏覽器
http://ubuntu-virtualbox:8888/