Hadoop HDFS Java API 串接使用程式開發,相關步驟如下,請參考
一、設定hadoop eclipse plugin
參考網址: https://www.programmersought.com/article/26674946880/
1.下載 hadoop-3.3.1.tar.gz
https://hadoop.apache.org/
https://hadoop.apache.org/docs/stable/
2.下載 apache-ant-1.10.11-bin.tar.gz
https://ant.apache.org/bindownload.cgi
3.下載eclipse-jee-indigo-SR2-win32-x86_64.zip
https://www.eclipse.org/downloads/packages/release/indigo/sr2
4.解壓縮及設定環境變數
1) 解壓縮以下檔案
hadoop-3.3.1.tar.gz 及 apache-ant-1.10.11-bin.tar.gz、eclipse-jee-indigo-SR2-win32-x86_64.zip
2) 設定環境變數
HADOOP_HOME=D:\04_Source\tool\hadoop-3.3.1
ANT_HOME=D:\04_Source\tool\apache-ant-1.10.11
PATH加上%ANT_HOME%\bin and %HADOOP_HOME%\bin
5.下載eclipse-hadoop3x專案及調整設定
1) 下載以下github內容eclipse-hadoop3x
https://github.com/Woooosz/eclipse-hadoop3x
2) 調整ivy/libraries.properties
將
hadoop.version=2.6.0
commons-lang.version=2.6
slf4j-api.version=1.7.25
slf4j-log4j12.version=1.7.25
guava.version=11.0.2
netty.version=3.10.5.Final
調整成同hadoop版本
hadoop.version=3.3.1
commons-lang.version=3.7
slf4j-api.version=1.7.30
slf4j-log4j12.version=1.7.30
guava.version=27.0-jre
netty.version=3.10.6.Final
3) 調整src\contrib\eclipse-plugin\build.xml
a.將
<target name="compile" depends="init, ivy-retrieve-common" unless="skip.contrib">
調整成
<target name="compile" unless="skip.contrib">
b.於此行下
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/htrace-core4-${htrace.version}.jar" todir="${build.dir}/lib" verbose="true"/>
增加
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/woodstox-core-5.0.3.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/stax2-api-3.1.4.jar" todir="${build.dir}/lib" verbose="true"/>
c.將
<fileset dir="${hadoop.home}/libexec/share/hadoop/mapreduce">
<fileset dir="${hadoop.home}/libexec/share/hadoop/hdfs">
<fileset dir="${hadoop.home}/libexec/share/hadoop/common">
...
<fileset dir="${hadoop.home}/libexec/share/hadoop/mapreduce">
<fileset dir="${hadoop.home}/libexec/share/hadoop/common">
<fileset dir="${hadoop.home}/libexec/share/hadoop/hdfs">
<fileset dir="${hadoop.home}/libexec/share/hadoop/yarn">
...
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/protobuf-java-${protobuf.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/log4j-${log4j.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/commons-configuration2-${commons-configuration.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/commons-lang-${commons-lang.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/commons-collections-${commons-collections.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/jackson-core-asl-${jackson.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/jackson-mapper-asl-${jackson.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/slf4j-log4j12-${slf4j-log4j12.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/slf4j-api-${slf4j-api.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/guava-${guava.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/hadoop-auth-${hadoop.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/netty-${netty.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/htrace-core4-${htrace.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/woodstox-core-5.0.3.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/libexec/share/hadoop/common/lib/stax2-api-3.1.4.jar" todir="${build.dir}/lib" verbose="true"/>
...
lib/woodstox-core-5.0.3.jar,
lib/stax2-api-3.1.4.jar,
調整成同hadoop上同樣的路徑
<fileset dir="${hadoop.home}/share/hadoop/mapreduce">
<fileset dir="${hadoop.home}/share/hadoop/hdfs">
<fileset dir="${hadoop.home}/share/hadoop/common">
...
<fileset dir="${hadoop.home}/share/hadoop/mapreduce">
<fileset dir="${hadoop.home}/share/hadoop/common">
<fileset dir="${hadoop.home}/share/hadoop/hdfs">
<fileset dir="${hadoop.home}/share/hadoop/yarn">
...
<copy file="${hadoop.home}/share/hadoop/common/lib/protobuf-java-${protobuf.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/log4j-${log4j.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-configuration2-${commons-configuration.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-lang3-${commons-lang.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-collections-${commons-collections.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/jackson-core-asl-${jackson.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/jackson-mapper-asl-${jackson.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/slf4j-log4j12-${slf4j-log4j12.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/slf4j-api-${slf4j-api.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/guava-${guava.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/hadoop-auth-${hadoop.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/netty-${netty.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core4-${htrace.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/woodstox-core-5.3.0.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/stax2-api-4.2.1.jar" todir="${build.dir}/lib" verbose="true"/>
...
lib/woodstox-core-5.3.0.jar,
lib/stax2-api-4.2.1.jar,
4) 調整src\contrib\eclipse-plugin\build.xml
<javac
encoding="${build.encoding}"
srcdir="${src.dir}"
includes="**/*.java"
destdir="${build.classes}"
debug="${javac.debug}"
deprecation="${javac.deprecation}">
調整成
<javac
encoding="${build.encoding}"
srcdir="${src.dir}"
includes="**/*.java"
destdir="${build.classes}"
debug="${javac.debug}"
deprecation="${javac.deprecation}"
includeantruntime="false"
>
6.建路徑
eclipse-hadoop3x\build\contrib\eclipse-plugin\classes
7.編譯eclipse-hadoop3x專案
切換至 eclipse-hadoop3x\src\contrib\eclipse-plugin 路徑下
執行以下指令
ant jar -Dversion=3.3.1 -Declipse.home=D:\Tool\eclipse\eclipse-indigo -Dhadoop.home=D:\04_Source\tool\hadoop-3.3.1
8.使用hadoop plugin
1) 將hadoop-eclipse-plugin-3.3.1.jar放到Eclipse dropins目錄
2) 重啟Eclipse
3) Eclipse
-> Window -> Open Perspective -> Other… -> Map/Reduce
-> New Hadoop location…. -> 理論上應該會開視窗設定hadoop連線,但失敗…此部份需再確認
二、開發HDFS Java API
1.請完成安裝Hadoop – 參考
於ubuntu 20.04安裝hadoop 3.3.1
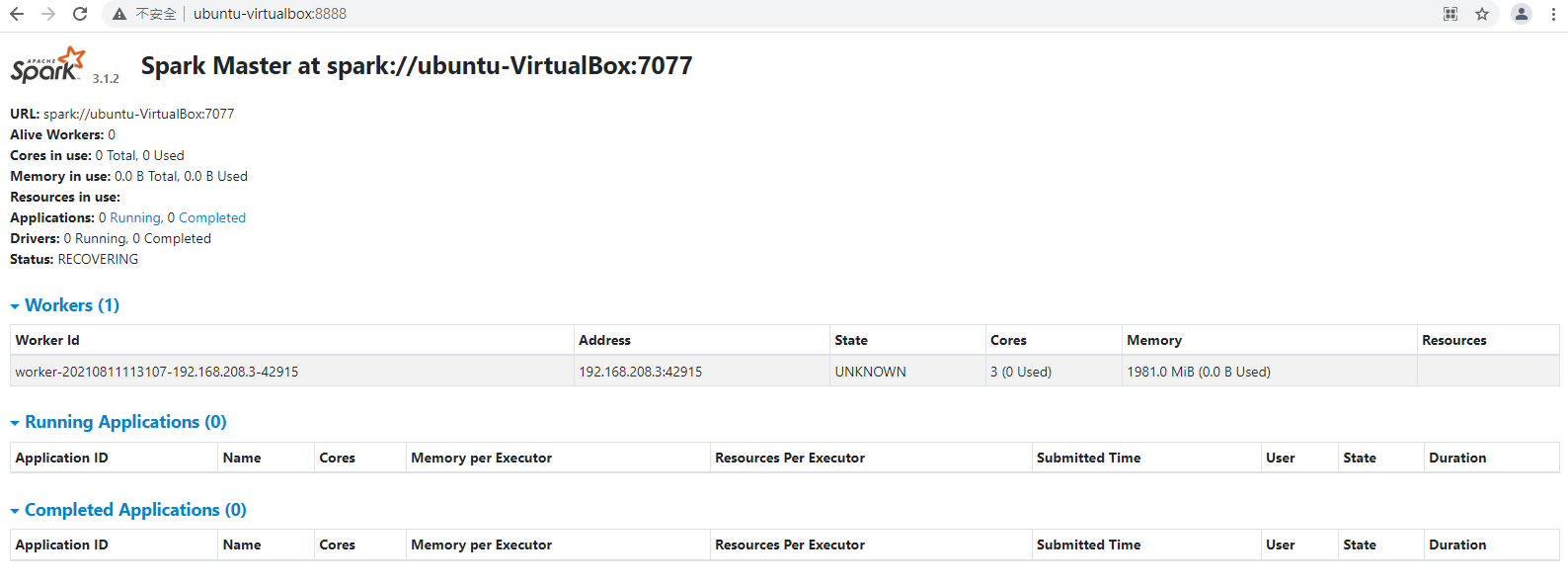
2.確認前一篇安裝的Hadoop hostname與測試的電腦所設定的IP是一致的
設定/etc/hosts其對應到程式可連線的IP (用telnet ubuntu-VirtualBox 9000)測試
192.168.208.3 ubuntu-VirtualBox
3.建置Eclipse專案,程式
package com.tssco.hadoop;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.io.IOUtils;
public class HDFSAPITest {
public static void main(String[] args) throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://ubuntu-VirtualBox:9000"), conf, "root");
//建立路徑
Path path = new Path("/data");
System.out.println("1.路徑/data" + " 是否存在: " + fs.exists(path));
boolean b = fs.exists(path);
if (!b) {
fs.mkdirs(path);
}
// 取得檔案清單
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(path, false);
System.out.println("2.取得檔案清單");
while (listFiles.hasNext()) {
LocatedFileStatus next = listFiles.next();
System.out.println(next.getPath());
System.out.println(next.getReplication());
BlockLocation[] blockLocations = next.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("\t子路徑: " + bl + ", size: " + bl.getLength());
}
}
System.out.println("3.取得檔案狀態");
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fst : listStatus) {
System.out.println("****** " + fst + " ******");
System.out.println("\t\t是否為路徑: " + fst.isDirectory());
System.out.println("\t\t是否為檔案: " + fst.isFile());
System.out.println("\t\tsize: " + fst.getBlockSize());
}
// 上傳檔案至/data/package
System.out.println("4.上傳檔案");
FileInputStream in = new FileInputStream(new File("D:\\04_Source\\test2.txt"));
FSDataOutputStream out = fs.create(new Path("/data/test2.txt"));
IOUtils.copyBytes(in, out, 4096);
// 上載檔案
System.out.println("5.下載檔案");
FSDataInputStream fsin = fs.open(new Path("/data/test2.txt"));
FileOutputStream fsout = new FileOutputStream(new File("D:\\test2.txt"));
IOUtils.copyBytes(fsin, fsout, 4096);
}
}
4.將/usr/local/hadoop/share/hadoop目錄下的common, hdfs, mapreduce, yarn 4個子目錄的jar文件放到專案的jar目錄
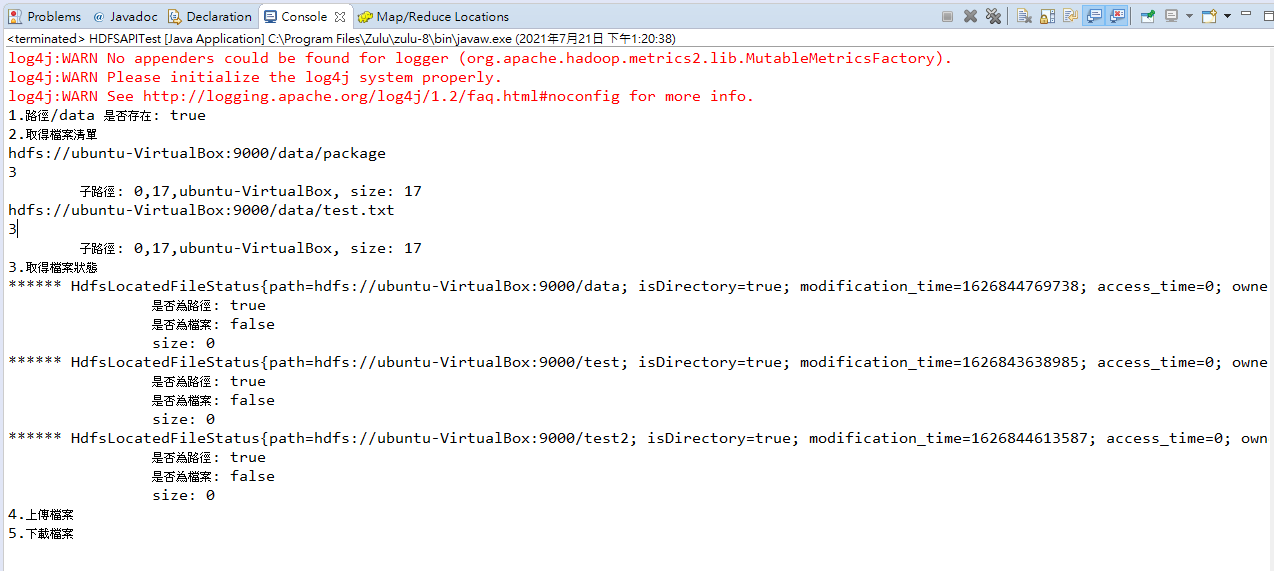
5.執行結果